





















6 minuten lezen
Gebruik van generatieve AI, kennisgrafieken en natuurlijke taalverwerking in MedTech-product- en codematching A
Medische benodigdheden omvatten een breed scala aan producten, van chirurgische instrumenten tot verbandmiddelen, die worden gebruikt in zorginstellingen. Het goed classificeren en toewijzen van codes aan deze medische benodigdheden is van cruciaal belang voor inkoop, tracering, facturering, bestelling, voorraadbeheer en patiëntveiligheid.
De belangrijkste uitdagingen zijn de hoge kosten van transacties in de toeleveringsketen in de gezondheidszorg (tot 4x hoger in vergelijking met andere industrieën), aanzienlijke verspilling, bijv. 5 miljard dollar aan COVID-19 PBM’s die als ‘onbruikbaar’ worden beschouwd. Bovendien werd wereldwijd 10% tot 34% van de uitgaven voor gezondheidszorg in OCED-landen verspild aan ongeschikte zorg.
We hebben de uitdaging onderverdeeld in code-to-code, code-to-product, product-to-product, product-to-evidence en product-to-opportunity. Meer specifiek
- Code-naar-code: stel je hebt een code zoals CPV en je wilt deze matchen met je eigen interne code of andere codes zoals UNSPSC.
- Code-naar-product: stel dat je als inkoper een nieuwe leverancier binnenhaalt met 30.000 artikelen of artikelen waaraan je categorieën moet toewijzen. Als leverancier moet ik de koperscode filteren of toewijzen aan mijn producten.
- Product-tot-product: als inkoper heb ik veel producten in mijn mandje met goederen, van verschillende merken of leveranciers, hoe kun je de producten vergelijken om vergelijkbare producten te vinden? Hoe kan ik als leverancier het marktlandschap begrijpen.
- Product-naar-bewijs: nu wil je als inkoper het klinisch bewijs van veel producten screenen, hoe doe je dit op dit moment? Als leverancier wil ik zien wat mijn concurrenten doen.
- Product-naar-kansen: als koper wil ik de producten van de leverancier zien, of als leverancier wil ik de kansen zien waaraan ik kan deelnemen of die mijn concurrenten doen.
Hier volgt een selectie van de complexiteit van classificatie:
- Complexiteit, diversiteit en standaardisatieproblemen: De enorme verscheidenheid aan medische benodigdheden, elk met zijn eigen unieke specificaties, maakt classificatie ingewikkeld. Het kan een uitdaging zijn om producten met kleine variaties van elkaar te onderscheiden. Er kan een gebrek zijn aan gestandaardiseerde naamgevingsconventies en categoriseringen voor medische hulpmiddelen, vooral tussen verschillende fabrikanten of landen. Verschillende leveranciers kunnen verschillende namen, codes of specificaties gebruiken voor vergelijkbare producten, waardoor het een uitdaging wordt om een gestandaardiseerde classificatie te handhaven.
- Voortdurende evolutie van producten: Naarmate de medische technologie voortschrijdt, komen er voortdurend nieuwe producten op de markt. Het up-to-date houden van classificatiesystemen wordt een voortdurende taak.
- Overlappende categorieën: Sommige medische hulpmiddelen kunnen in meerdere categorieën passen, wat leidt tot verwarring over de juiste classificatie.
- Menselijke fouten, schaal en vaardigheid: Er kunnen fouten optreden bij handmatige invoer of categorisatieprocessen, wat leidt tot verkeerde classificaties. Personeel moet worden opgeleid om het classificatiesysteem te begrijpen en correct te gebruiken, en deze opleiding moet worden bijgewerkt naarmate het systeem evolueert.
- Regelgeving en naleving: Verschillende regio’s of landen kunnen verschillende regels hebben met betrekking tot medische benodigdheden, wat invloed kan hebben op de manier waarop ze moeten worden geclassificeerd of gecodeerd. In multinationale omgevingen kunnen vertaling en lokalisatie de classificatie nog ingewikkelder maken.
- Interoperabiliteit en integratie: Verschillende systemen binnen een gezondheidszorginstelling, zoals facturering, elektronische patiëntendossiers en voorraadbeheer, moeten naadloos met elkaar communiceren. Discrepanties in codeclassificaties kunnen leiden tot problemen bij deze integratie. Oudere systemen in ziekenhuizen of instellingen kunnen nog steeds gebruik maken van verouderde classificatiesystemen, wat kan leiden tot discrepanties bij de integratie met nieuwere systemen of leveranciers. Classificatiesystemen moeten compatibel zijn met voorraadbeheersystemen om het gebruik van medische benodigdheden en de behoefte aan aanvulling naadloos te kunnen volgen.
Het aanpakken van deze uitdagingen vereist een combinatie van technologie, training en zorgvuldige planning. Oplossingen kunnen onder andere bestaan uit het investeren in moderne voorraadbeheersystemen, het geven van doorlopende training aan het personeel, samenwerken met leveranciers voor standaardisatie en het regelmatig herzien en bijwerken van classificatiesystemen. Het is niet mogelijk om dit wereldwijd handmatig te doen voor alle producten en diensten in de gezondheidszorg en hiervoor is een geautomatiseerde tracking- en monitoringoplossing nodig. Gelukkig is dit mogelijk met de opkomst van big data, generatieve AI en graph analytics.
ChatGPT-4 mag dan goed zijn in het samenvatten van tekst, onze datawetenschappers hebben ontdekt dat het gebruik ervan voor code-naar-code matching, zoals GMDN naar UNSPSC, ertoe leidt dat onjuiste classificatiecodes worden toegewezen, zelfs na zorgvuldige voorbereiding van de gegevens. Deze onnauwkeurige antwoorden zijn een proces dat bekend staat als hallucinatie en dat veel in de pers is besproken als een groot probleem voor het vertrouwen en de kwaliteit. Bij het matchen van product-naar-code kan het ook snel uit de hand lopen door de ruis.
Vamstar heeft veel ervaring met geavanceerde datawetenschap en kunstmatige intelligentie in de gezondheidszorg en MedTech-sectoren. We hebben toonaangevende Innovate UK Research- en AI Venture-financiering ontvangen en werken actief samen met toonaangevende universiteiten.
We hebben baanbrekende oplossingen ontwikkeld in de vorm van een platform, aangedreven door AI-technologieën, om de standaardisatie en geautomatiseerde catalogisering van producten/diensten in de gezondheidszorg mogelijk te maken, verrijkt met informatie uit heterogene bronnen om de besluitvorming over inkoop te verbeteren.
We hebben de grootste openbare aanbestedingsdatasets ter wereld van inkopers zoals ziekenhuizen, klinieken en universiteiten verzameld, geëxtraheerd met behulp van NLP, genormaliseerd en verrijkt. We kennen bijvoorbeeld de live aanbestedingen voor MedTech-producten, de toegewezen leveranciers en aankooppatronen.
Tegelijkertijd hebben we producten en artikelen uit catalogi van fabrikanten, leveranciers en distributeurs verzameld, genormaliseerd en verrijkt met behulp van aangepaste natuurlijke taalverwerking en generatieve AI. Dit geeft ons een volledig inzicht in de portfolio’s en aanbiedingen aan de aanbodzijde.
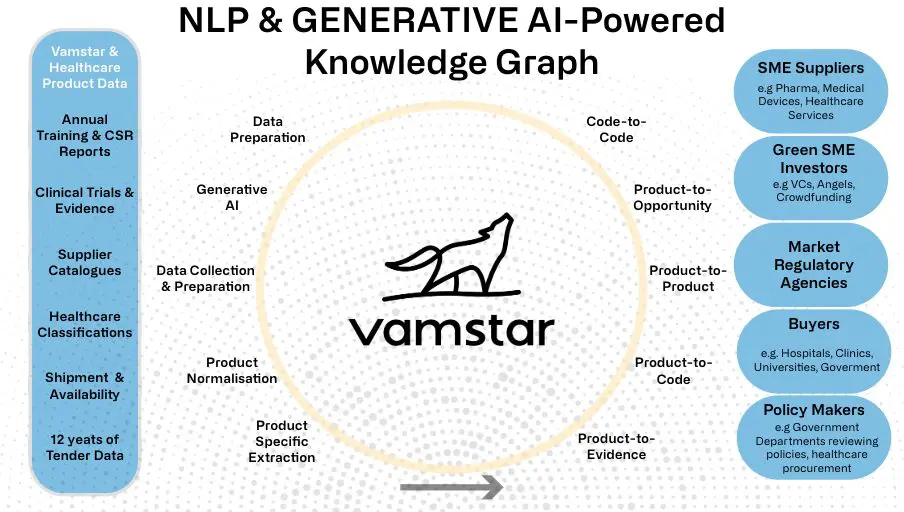
We combineerden deze twee enorme specifieke datasets voor de gezondheidszorg en MedTech en creëerden de grootste kennisgrafiek waarmee we op nooit eerder vertoonde hyperscale grafiekmatching van producten en codes kunnen uitvoeren op basis van low-level productkenmerken en specificaties in de gezondheidszorg in verschillende talen.
Het creëren van ‘s werelds grootste kennisgrafiek op het gebied van gezondheidszorg en biowetenschappen – die alle kopers, leveranciers, producten, diensten en medische hulpmiddelen in alle landen met elkaar verbindt – is een complexe taak waarvoor unieke vaardigheden en veel genormaliseerde en verrijkte gegevens nodig zijn. De onderliggende grafiek is gemaakt met behulp van complexe natuurlijke taalverwerking (NLP), generatieve AI en Machine Learning-modellen, waaronder het gebruik van GPU-instanties voor het trainen van onze aangepaste deep learning NLP-modellen. In samenwerking met de Universiteit van Sheffield, wereldleiders op het gebied van NLP, hebben we zowel de data die we verwerken als de knooppunten en relaties die worden weergegeven in de netwerkgrafiek opgeschaald.
We hebben drie geavanceerde technologieën van generatieve AI, verwerking van natuurlijke taal en kennisgrafieken in perfecte harmonie samengevoegd om al uw code- en producttoewijzingen en classificaties automatisch te matchen. Dit wordt georkestreerd met behulp van een complexe reeks eigen big data en machine learning-pijplijnen die eenvoudig in de cloud kunnen worden opgeschaald.
We hebben de unieke mogelijkheid om zeer schaalbaar en nauwkeurig te werken:
- Code-naar-code: Automatische matching van CPV, UNSPC, GMDN, GUDID, UDI, eClass en interne code/catalogus/taxonomie.
- Code-naar-product: Wijs CPV, UNSPC, eClass of interne code/catalogus/taxonomie toe aan producten.
- Product-naar-product: producten vergelijken met andere producten en een matchingscore geven.
- Product-naar-bewijs: vat het klinisch bewijs voor een product of productgroep samen.
- Product-naar-opportuniteit: we kunnen een aanbesteding of privéopportuniteit koppelen aan producten van een leverancier.
Vamstar is het toonaangevende AI-aangedreven B2B Healthcare and Lifesciences Exchange platform, dat meer dan 750 miljard dollar aan uitgaven verzamelt en analyseert van 86.000 kopers van publieke en private bronnen van producten en diensten in de gezondheidszorg in meer dan 100 landen. Vamstar’s cloudgebaseerde supply chain-technologie verbindt zowel kopers als leveranciers om belangrijke bedrijfsprocessen te automatiseren, waarbij gegevens en op resultaten gebaseerde analyses worden omgezet in zinvolle actie voor het ecosysteem van de gezondheidszorg om snel te handelen, efficiënt te opereren en grote synergieën te bereiken, waardoor betere patiëntenzorg mogelijk wordt en de besparingen in de sector voor haar klanten worden gemaximaliseerd.
We maken gebruik van Big Data en Machine Learning om slimme inkoop, snellere aanbestedingen, vereenvoudigde contractering, real-time kansen, ingebedde intelligentie en aanverwante diensten mogelijk te maken, waaronder de webgebaseerde handel in gezondheidszorgproducten tussen ziekenhuizen, klinieken, laboratoria en leveranciers in de markt.
Door het grote geheel en alle verbindingen te zien, biedt Vamstar belanghebbenden in de gezondheidszorg waardevolle marktinzichten en -perspectieven. Vamstar werkt samen met leiders in de industrie, de academische wereld en de overheid in meer dan 100 landen om het denken op een hoger niveau toe te passen op dagelijkse taken en strategische kwesties. Ze bieden hun klanten oplossingen om hen efficiënter te maken en hen te helpen datagestuurde geïnformeerde beslissingen te nemen om hun toekomst veilig te stellen.
Andere materialen






Boek een afspraak van 30 minuten met ons
Welkom op onze planning pagina! Kies hieronder een beschikbare datum om te beginnen.

30 minuten vergadering

We sturen je de link van de vergadering per e-mail